
Why I'm Not a Security Doomer
Preventing theft of AI systems is hard. But sometimes it's worth it, and protecting model weights specifically is a good target.

I have recently – in a somewhat joke-y way – started using the term “security doomer.” By security doomer, I mean people who think that AI systems can’t be protected from theft by sophisticated state attackers, or at least that protecting them would slow down AI research so much that it isn’t worth the effort.
This is a reasonable perspective, since securing anything against sophisticated attackers is in fact super hard. Attackers have a bunch of advantages (like only needing to succeed once and having many possible ways in), enormous resources (the Stuxnet attack reportedly cost around a billion dollars to carry out), and very strong incentives to succeed.
Ultimately, I am not a doomer myself, but in order to understand why, we need to first understand where such folks are coming from.
Note: while sometimes people (myself included) use the term “security” to refer to various things, including preventing misuse of AI, I’m here just going to be talking about information security.
Why Doomerism Is Appealing
Information security is hard
There are countless examples of information security failures – because it’s a hard problem.
Chinese hackers stole millions of extremely sensitive security clearance applications from the US’s Office of Personnel Management (OPM). US critical infrastructure is so thoroughly penetrated by attackers that it will reportedly take years to even fully understand how bad it is, let alone fix it. Despite Iran taking very serious steps to keep the Natanz uranium enrichment complex secure, Israel and the United States still sabotaged it. For a longer list, see Appendix A in this report.

The apex predators of the security world. It’s very hard to defend against these. Image from the report linked above.
Information security in general is hard, and protecting AI systems in particular is also hard. AI software and hardware are super complex. There are many dependencies in the AI supply chain, making it hard to even understand, let alone safeguard. Each company uses products, data, hardware, and code from many sources. Everything is constantly changing and breaking. Employees will get annoyed when you ask them to do fairly standard things like use a company phone or use 2-factor authentication for everything, let alone something more severe like not bringing electronics to the office. And you can’t always trust your employees, who might be spies or coerced by third parties to compromise your company.
Security is costly in AI
As alluded to above, people at companies generally don’t love implementing new security measures. Why? Because it’s expensive – not so much in terms of direct costs (though you do need to hire people, buy some hardware/software, etc.), but rather, it’s expensive in terms of slowing things down. Of course, if you invest too little in security and have a major incident that destroys the reputation of the company, that will really slow you down later. But that’s a concern for later, and people aren’t great at planning for the long-term. It’s also not totally clear that there will really be costs for the company later due to bad security. Maybe the company gets hacked but the public never finds out, so users and national security could be damaged while the company pays no direct financial or reputational price.
What does this look like concretely in the case of AI companies trying to improve their security while also competing on the market? If security is dramatically ramped up in a unilateral fashion by a company, it will slow down research and slow down shipping of products. I’ll return later to ways that the costs can be decreased through collective investments in e.g. R&D, but the point here is that there are in fact costs. For example, let’s say you want to protect model weights from theft by making it so that fewer employees can access them. That means that, all else equal, it’s harder for some people to contribute to the project. And if you start compartmentalizing information about AI models and algorithms, fewer “eyeballs” are on various research problems, potentially slowing progress.
There are also AI-specific vulnerabilities, like distillation attacks, in which an attacker takes a shortcut on creating a similar model by “distilling” the intelligence reflected in your model, by training on outputs from the model rather than the weights themselves. It seems hard to defend against these without making your product less useful. And there are many different things to protect – not just model weights (which we’ll discuss in more depth later) but also product plans, customer data and customer identities, algorithmic insights, code, etc. Oh, and people move between companies all the time, bringing secrets with them.
Costs matter
It’s not just that there are costs, but that companies are, rightly, cost-conscious.
No company is more than a few months ahead of their closest competitor in the current “main arena” of competition (large pre-trained language models fine-tuned with reinforcement learning, and then run with a lot of inference compute). Some have bigger leads in very specific areas but not in the main arena. These companies are in my view a bit further ahead of DeepSeek (let alone other Chinese companies) than some commentators appreciate, in large part because of compute. But now that DeepSeek is (informally) China’s national champion on AI, that could change quickly as a larger fraction of Chinese compute gets steered towards them.
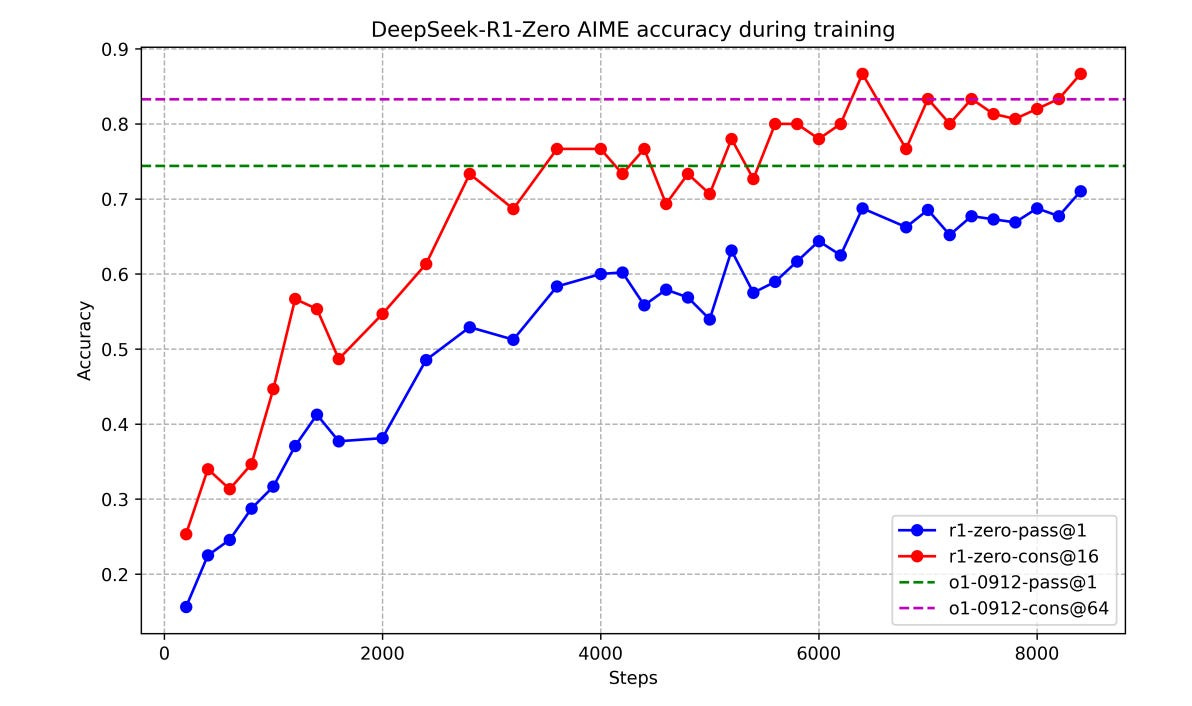
Graph from DeepSeek’s R1 paper, showing a similar approach to what OpenAI demonstrated a few months prior — reinforcement learning to elicit progressively longer and more useful “chains of thought.” See also this post.
Given this competitive situation, if a security intervention slows a company’s research or product development down by, say, 50%, or would cause researchers to be so annoyed that they all leave to join a competitor down the street (or worse, leave the country), it’s simply untenable from the company’s perspective. Most security interventions don’t have that big of an effect, but if you did everything at once it would be quite disruptive, so companies are gradually ratcheting things up bit by bit, doing the most that they think they can afford – which is not going to be enough to prevent sophisticated nation-state attackers from stealing the extremely powerful systems that will exist very soon. Indeed, this is acknowledged by the companies in question, which, depending on the company, either set their ambitions lower in the near-term (i.e., they acknowledge they are not there yet but are working gradually towards it), and others don’t even aspire to defend against sophisticated attackers.
Additionally, some of the “classic” approaches to achieving extreme security are simply not viable in the context of AI (e.g., requiring everyone involved in frontier American AI companies to have a security clearance is not viable given how many non-citizens are critical to the functioning of these companies). And AI research requires conversation, access, dynamism, etc. in a way that may be different from (e.g.) keeping a well-defined, decades-old nuclear weapon system humming. In that sense, the “costs” of applying some extreme measures in an AI context are potentially infinite because they could eliminate the very advantage that is purportedly being protected.
Given all of this, it is reasonable to ask – is it really worth it to protect AI systems against the most sophisticated attackers, or will that just slow things down to the point of being counterproductive? Maybe the best we can hope for is something like mutually assured destruction, as some recently argued.
The case against doomerism
Security is hard, it’s costly, and the companies on the frontier can’t afford the huge costs that would be required to secure their systems against all possible attackers — at least if they’re trying to sort it out themselves, and if they are aiming for perfection (e.g., never leaking algorithmic ideas, product plans, etc.). But I think we can set our sights on something more tractable, and work together towards a solution that protects (part of) the most important systems.
The question is not whether we should apply very rigorous standards of security to all systems but whether we should do it sometimes – and to figure out how to do it at the lowest possible cost. I think we should, and that the most realistic (and still useful) goal of such efforts is protecting model weights.
Model weights are weighty
When GPT-4.5 was released recently, OpenAI staff joked a lot about how it was a “chonky” model. That is, it has a lot of parameters, so running it requires a bunch of GPUs to make a bunch of calculations. Model weights are not the entirety of an “AI system,” which may comprise an interface, some tools, various ways of really pushing those model weights harder and longer to get better answers than the model’s first intuitive guess (i.e., ways of “applying test-time compute”), etc. But, the weights are at the center, and I think they will sometimes be worth protecting, and relatively soon.
GPT-4.5 is probably not the chonkiest model that there will ever be, and based on public speculation about the size of GPT-4, it probably has many trillions of parameters. But let’s be conservative and pretend that it is just a trillion parameters, and that models won't get any bigger. If that were true, then models would be a few terabytes in size, depending on the precision.

Screenshot of this tweet.
If you were to write down each model parameter one by one on a piece of paper, and could write one per second, it’d take hundreds of thousands of years. Of course, computers and cables can transmit such files much more quickly than humans can write them down. But not infinitely fast, and they can also be designed with “speed limits” on certain types of activities. Given that almost all uses of AI – even by researchers at these companies – do not require direct access to the model weights, this is a very promising fact. It means that we can potentially design systems that are useful (allowing many forms of access to AI systems) while being secure in at least one specific sense (making it very hard to exfiltrate the weights from a datacenter). This is not by any means trivial but I have yet to see an argument as to why it’s impossible.
One response to this is that model weights aren’t that important anyway–didn’t DeepSeek replicate o1 with just a few million dollars? Well, the total cost (not just the training cost) was definitely way higher than that, but let’s pretend that it was. GPT-4.5 certainly cost much more, and will certainly be much more capable when reinforcement learning is applied to it at scale, compared to DeepSeek’s current models. Eventually, DeepSeek will be training models that cost hundreds of millions of dollars or billions of dollars just in terms of marginal training costs – and by then, US companies will (assuming the US government doesn’t back down on export controls) be even further along.
The important thing is that there will always be some model weights we want to protect very well, whether they are ones that cost billions of dollars, or ones trained on very sensitive data or performing very sensitive tasks, etc. Whether some weights aren’t worth protecting is separate from whether we should build the technologies to protect some weights.

AI training is getting expensive, and training runs will soon cost more than the cost of executing the Stuxnet attack (if they don’t already). Taken from here.
Similar points can be made about model distillation as a possible counter-argument to investing in weight security: what is the point of protecting the weights if you can just distill the model by sampling from it? Well, first of all, I’d note that the impact of distillation is sometimes overstated – even if one granted that DeepSeek’s R1 was partly based on distilling from o1 (which I haven’t seen conclusively demonstrated), it was still not as performant as OpenAI’s best models on various benchmarks. The science of distillation is still fairly early but it seems to me that there will probably be some cases in which distillation will not be enough and an attacker will still want to get the actual weights (for example, perhaps this happens in cases where it matters a lot what the base model is). In those cases, we should know how to defend model weights.
Security does succeed sometimes
It’s been a while since San Francisco or New York got nuked. Actually, they never have, despite there being a large number of really bad folks out there who would love to. Why? Because nuclear weapons are pretty well protected and controls on their use are pretty good. It’s not literally impossible to steal them or for someone to launch a nuclear missile illicitly, and there have been some close calls. There was a pretty close call at the end of the Cold War, when the US and Russia worked closely to lock up nuclear weapons while the Soviet Union collapsed. But generally speaking, major investments in security have paid dividends, and made it so that it’s more cost effective to just build your own (or, at least, building your own is less likely to get you killed than trying to steal one, though still somewhat likely to get you killed).
You might say that this is not analogous to AI, because nuclear weapons aren’t being used all the time, so of course it’s easy to keep them secure. Well, yes, that’s true, but a primary concern of nuclear planners is making sure that if and when they are needed, those weapons will be available. That’s how nuclear deterrence works, and again, lots of people spend a lot of time making sure this is the case (while also safeguarding these weapons from theft and misuse). Like, literally billions of dollars and hundreds of thousands of person-years have been spent on this problem. So it is in fact possible to reconcile usability with security.
But can security be done for something used by billions of people? Yes. Look at cryptography, for example. Private keys that, if stolen and misused, would be worth billions of dollars (e.g., those of root CAs), are routinely protected from theft. As a result, public key cryptography undergirds a global system that generally allows people to send emails and buy products and services securely online.
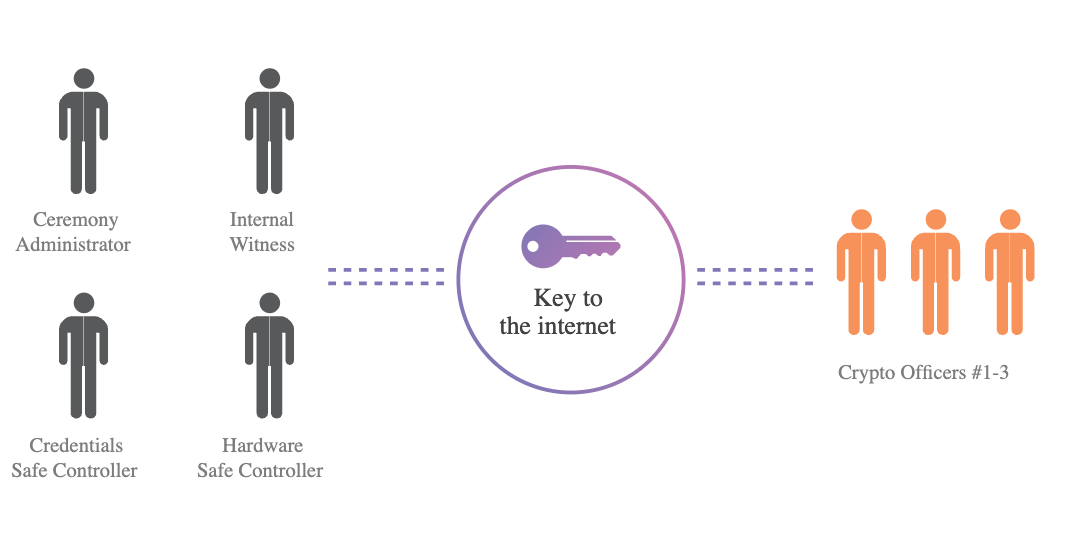
From Cloudfare’s description of the steps they take to secure their most sensitive stuff. From this blog post. See also this from ZCash. Sometimes security is worth it.
I don’t mean to downplay the difficulty of security. Sometimes really damaging attacks happen, and smaller ones happen constantly. A huge amount of critical infrastructure in the US is cooked and this would be exploited in the event of a war.
But typically the way these attacks happen is that someone exploits an issue with the software, or “hacks” the people involved, rather than, e.g., infiltrating a deep vault with a super secure safe at the bottom with a USB stick on it. My claim is that with the right software and hardware design, we can make model weights more analogous to the deep vault scenario, while still letting “good” traffic go in and out of the vault through well-understood channels.
Weights are chonky, and also, like private keys in cryptography, not everyone actually needs to directly access them (and indeed it can be counterproductive for everyone to have direct access to them). APIs for OpenAI, Anthropic, and DeepMind provide users with the ability to sample from and even sometimes fine-tune AI models, without taking them. Sometimes these APIs are designed in the wrong way and actually you can steal (parts of) them, but that seems like a solvable technical problem. Between good software and hardware design, it seems possible to make AI systems that are useful for a very wide range of purposes while making the costs of stealing them much greater than the costs of recreating them.
For further related discussion, see Appendix B of this report.
Costs can be driven down and shared
As discussed above, costs matter in AI. But that doesn’t mean everyone should have to fend for themselves.
In fact, that’s part of why governments invest in research and development – companies may not fully capture the benefits of such investments so they may not invest as much in them as is ideal for society as a whole. Breakthroughs in science and technology can benefit everyone, and should often be subsidized. Indeed, in the nuclear context, this happens all the time – countries that have more sophisticated security controls for nuclear weapons will help other countries to secure their own stockpiles, because (pretty much) no one benefits from loose nukes.
Also, different security tools and practices can get easier and cheaper over time through innovation. Widely used security tools like single sign-on (SSO) make things both more secure and easier for users, and while there are probably some irreducible costs to very good security in AI, we won’t know how cheap we can make it until we try.

You can just do things (and thereby make them cheaper for others to do them). From this page. We don’t really know what the experience curve for weight security looks like, but the best way to find out is to do more research and pilots and share what’s discovered.
So, again, I am on the side of optimism regarding the (partial) solvability of AI security. With government leadership and different companies contributing to different parts of the problem and publishing their results, the overall “waterline” of the sector can be driven upwards, at much lower cost than if everyone had to figure it out on their own.
Two areas in particular jump out as priorities for urgent investment:
Confidential computing features: This class of technologies is considered by many experts to be a key building block of weight protection, but by all accounts the features available today are not scalable to production-size model weights, nor has there been sufficient testing of them to have confidence in robustness against serious attackers. Several steps could potentially help here: government and philanthropic support for related research and development, tax credits or other incentives for chip companies to speed up the timeline of making this technology viable in production settings, and a commitment to consider the availability (or lack of availability) of such features in future government contracts. There should be widespread and well-resourced testing of these systems before going into production to the extent possible, or it will be difficult to have confidence in the lack of vulnerabilities.
Open source, well-documented secure API designs: Companies (and national security agencies using AI) will always have a need to build some custom security software internally, due to the quirks of their particular software and hardware set-ups, we shouldn’t overestimate the similarities between AI systems across companies, either. Governments and philanthropists could thus support the development of well-maintained and well-documented software libraries that demonstrate how to provide internal employees with the ability to sample from and fine-tune models while still having strong security guarantees against exfiltration, and this investment could improve security at many companies simultaneously. It is not uncommon for a company to use the exact same model architecture (e.g., because they have fine-tuned an open source model), and there are many high-level similarities between models at different companies (e.g., using autoregressive Transformers and using some kind of mixture-of-experts approach). Additionally, companies often use some of the same software, like Kubernetes, which predictably introduces various security risks, and public resources to defend against such risks could be very valuable especially to less-resourced AI developers and deployers. Comprehensive coverage of all possible security situations that a company might encounter is impossible but you could imagine, e.g., a resource that provides worked examples of securing Llama weights on GPUs, a generic mixture-of-experts model on TPUs or Trainium chips, etc., and AI developers and deployers could take inspiration from these examples rather than starting from scratch.
A realistic vision of success
I suspect it will be too costly to try to protect a big fraction of algorithmic secrets. They are easy to “save” (in one’s head) and transmit (by saying a sentence or two to someone). But those algorithmic secrets are only valuable because they are used on computing hardware (which is relatively governable) and because they allow you to make better model weights or use those weights more effectively. And most computing hardware is used for running model weights, not training them. At the end of the day, it does matter who has the most capable weights and who doesn’t. And I think we can achieve weight security for the most capable models.
What would this (partial) security success story look like in practice? For details on some of the technical challenges involved, see the RAND report discussed above, but here’s a very rough personal sketch:
Frontier AI companies have very high confidence that weights won’t leave their datacenters without multiple parties signing off on such a transfer. Depending on the sensitivity of a particular model, this “high confidence” can be arbitrarily increased by toggling the “security vs. convenience” knob. This level of security is verified repeatedly by highly-resourced penetration tests.
Cables going in and out of the datacenter are heavily scrutinized for tampering, and there is software and hardware on both ends of each cable guaranteeing that only certain kinds of data and instructions can flow through them. For example, perhaps there are certain “white-listed” queries and responses that can go through at a certain volume each day, and anything not fitting this data structure will trigger a careful review.
Extensive physical security would be applied at the datacenter (“guns, guards, and gates”) – while chips would be designed in such a way that no one should be able to steal the weights through direct access, defense-in-depth will still be needed to be really sure. For example, no one should get anywhere near the chips without several people knowing exactly what they’re doing and watching their every move.

Cables at a datacenter - taken from here.
Obviously you don’t want to do this for all AI systems (which I’ll revisit in the conclusion shortly). But sometimes you should do it, and we need to figure out how to do all of this as cheaply and efficiently as possible for the few cases where it’s needed.
Also, I’m not saying that in the ideal case, no one should ever protect anything other than weights. Of course a company should protect user data from at least non-state attackers. “Normal security” is critical for frontier AI companies as well as companies applying AI in critical applications. And some algorithmic secrets are probably worth protecting for at least some period of time. The question is just what, if any, large-scale, cross-industry and cross-sector moonshots we should be betting on in the context of AI information security, and I think weight security is a good target for that.
Conclusion
I want to again underscore that security is hard and costly and that costs matter. Not every AI system should be under lock and key. We get lots of benefits from some models being open sourced, for example, and I don’t personally want to have to jump through a zillion hoops to use ChatGPT.
But we need to think of secure AI as an investment that will be needed for some purposes, and which is currently not moving at the speed of AI progress. I’d like to see cross-sectoral work to drive down the costs of very good weight security as quickly as possible.
If you work at an AI company, try to be part of the solution to security. I’m not saying you shouldn’t complain when something your company does is actually “security theater” that isn’t worth the effort – but conversely, there may be things your company could do that are worth it, and maybe you should speak up for your security team from time to time and see if there are engineering problems they’re working on that you can help with. And then see if you can share the results with the world, driving down costs for others.
There’s a lot of active work in this area and I’ll share more about it — and ideas for policies that could speed things up — in future posts.
Acknowledgments: Thanks to Lennart Heim, Sella Nevo, Carly Tryens, Jason Clinton, Katherine Lee, and Larissa Schiavo for helpful comments. The views expressed here are my own.