
AI is a Liquid, Not a Solid
The variable amount of AI that you have, and AI's propensity to spread all over the place, make it a lot like a liquid.

Introduction
The analogies that we use when talking about AI influence which aspects of the technology we pay particular attention to, and which solutions we develop and find tractable. Is AI like electricity, the printing press, the Internet, or nuclear weapons? Is it like none of these things, or like all of them in different ways? Will it be like one technology at one stage, and then like another technology (or even more like a species) at a later stage?
I don’t think there is a single best analogy, and there is no substitute for studying the actual technologies, impacts, and organizations involved in AI. But I want to describe one idea that I’ve been thinking a lot about lately, and which sheds some light on key debates in the field. The idea is that “AI is a liquid, not a solid.”
In literal terms, AI systems are trained by, and run on, solid machines (computing hardware). Those in turn are powered by electricity, cooled by air or liquid, and the ideas behind all of this are non-physical. But when I say that “AI is a liquid, not a solid” metaphorically, I’m trying to make a point about the amount of AI that exists and that people have access to, and about the ease with which AI spreads. Both of these properties have many implications in an AI policy context, so I think it’s useful for more people to internalize this analogy.
Amounts of AI
It’s natural to think of a system like ChatGPT (or Claude, or Gemini, etc.) as a single, well-defined entity that is sitting in the cloud somewhere, waiting to respond to your question. But this is an increasingly misleading way of thinking about AI. The amount of AI capability that an AI system has, or that an organization has, is a matter of degree, rather than coming in discrete chunks.

The amount of thinking that you get out of AI increasingly depends on how much you pay in order to get a (literally) more thoughtful response. At first this involved just paying more for a version of the system that would think for longer (in a “chain of thought”) before replying, but now this is becoming more like a knob you can tune – you can set an exact “thinking budget” depending on how much thinking you want.
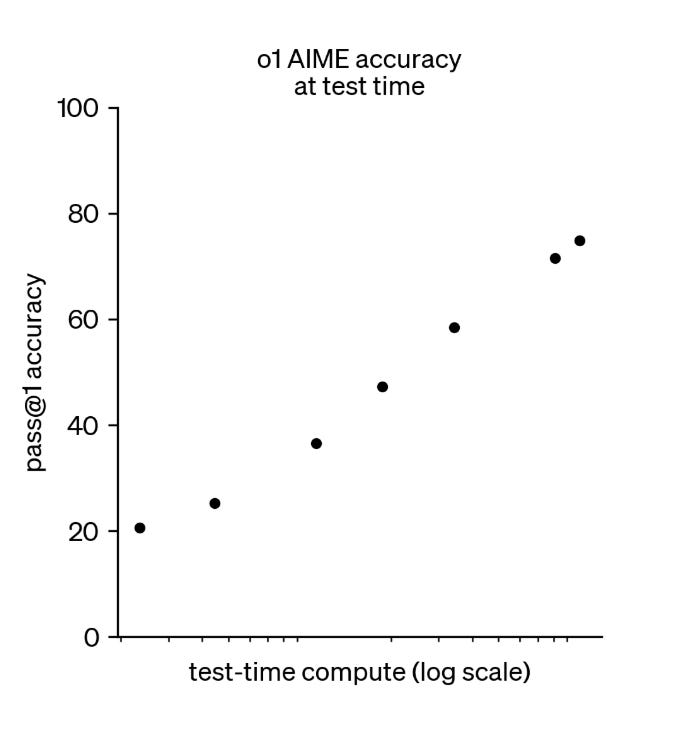
Figure from this post on o1.
The “liquid-ness” of AI is also true at the level of an AI platform, like the OpenAI, Gemini, or Claude API. The number of copies of each model is in constant flux as companies adapt to demand. It’s a bit like a bathtub that has water going in from the faucet and out through the drain - the bathtub constantly fluctuates in terms of the amount of liquid inside it, and so does the amount of “AI” in a datacenter.
If you look at the field of AI as a whole, progress is also “liquid-like” in the sense of coming in small increments rather than sharp breaks. There was no single, sharp point at which AIs began clearly “thinking,” “reasoning,” etc., and before which they clearly weren’t. Similarly, whether AI systems are “human-level” depends on which humans and set of tasks you’re talking about, and also how much you’re willing to pay in order to run the system.
Measuring quantities of AI is more like measuring a liquid than counting the number of LEGO blocks in a pile, where there’s a clear right answer. As with actual liquids, you can try to come up with measurements and definitions in order to make sense of the situation, such as quantitative evaluations for AI performance, and some people define “AGI” in various more precise ways than others. You can also define what a quart or a milliliter is, and then say that you have a quart of water or a milliliter of milk, but at the same time, scientists still recognize that these are ultimately human-made categories, rather than being inherent units of water or milk.1

Another liquid-like aspect of “amounts of AI” is that you can split up or combine different “AIs” or components thereof in many ways, just as you can transfer the contents of two containers of liquid into a bigger container, or vice versa. There’s a wide variety of ways that this can work. For example, AIs can be “chained together,” where the output of one becomes an input to another. AIs can also be “distilled” or “quantized” into a smaller version that is cheaper to run but a bit less capable, by training the smaller model on the outputs of the bigger one. You can also sometimes literally stitch together different (parts of) neural networks into a larger composite network.
There are a few policy implications to this liquid-ness of AI quantity:
This metaphor underscores why we should not wait for arbitrary milestones to be achieved in order for us to take AI seriously – the liquid is all there will ever be. AI is not going to freeze or crystallize into some solid, well-defined “AGI” tomorrow. We have a lot of AI already, and we are getting better at making more of it, drop by drop every day. That will be the case for the foreseeable future. There’s always a better model or system waiting to be built, there’s always a smaller one to be built and run more cheaply, and there’s always a way to run more copies of an existing one.
This framing also underscores the fact that we should not expect any company or country to have a monopoly on AI capabilities. Some liquid containers are bigger than others, but that is different from someone having a monopoly. There is no specific threshold — like the formation of a crystal — that only one organization can achieve. Because leadership in AI will always be a matter of degree, we should assume that if one company is capable of creating one kind of system, many others will be able to do so soon after, or even at the same time by spending more computing power to run worse algorithms. This has many implications I’ve discussed elsewhere, including the need for a degree of cooperation on safety and security between different AI efforts.
Access to AI
In addition to AI quantities being liquid-like, AI access is also liquid-like.

Liquids have a tendency to leak out of containers that aren’t well-constructed. Insights about AI technologies and products also often leak out if companies aren’t careful, and they are also easily shared by people who want to do so for licit or illicit purposes. More generally, AI developments tend to diffuse outward from their point of origin by default, absent rigorous efforts to contain them.
Sometimes we should actually apply the rigorous effort required to contain AI capabilities, such as when protecting frontier AI model weights from theft and tampering. Other times we should just accept and embrace the fact that AI gets everywhere and lean into the many benefits of that. But either way, our policies and our overall mental model of the technology needs to reflect AI’s ease of spreading.

Different levels of sophistication in stealing or tampering with AI systems. Currently, I’m not aware of any company that even claims to be able to reliably protect themselves against attackers above level 3, and most are not capable of defending at that level. Taken from this summary of this report.
When an AI model is released open source,2 it is not only copied many times but also modified in various ways, like a puddle spreading in many directions simultaneously. Likewise, it only takes a very small “crack” in a corporate “container” for an idea to spread far and wide, even if it isn’t accompanied by full details or model weights. OpenAI’s announcement of o1 was immediately followed by a huge array of new research projects in many countries, including DeepSeek’s R1-preview and then later R1, despite OpenAI having provided only a very small amount of information in the original post. Just showing that something is possible, and roughly what technical direction is required, is often more than enough to motivate talented teams to follow in a leader’s footsteps, and sometimes match or exceed them.3
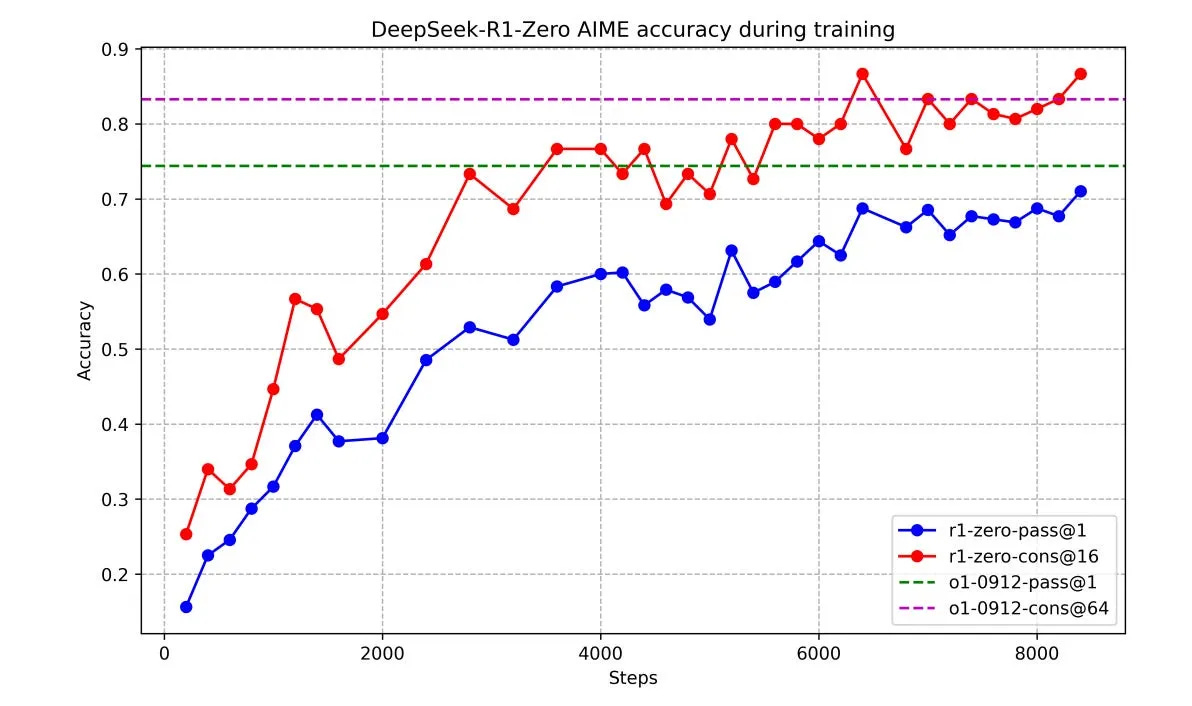
Graph from DeepSeek’s R1 paper, showing a similar approach to what OpenAI demonstrated a few months prior — reinforcement learning to elicit progressively longer and more useful “chains of thought.” See also this post.
Some very simple ideas in AI are worth millions to billions of dollars, in terms of the computing power they could save or the capabilities they could help reach. But different aspects of AI have different “viscosity” and propensity to spread. Hardware spreads less easily than algorithmic ideas – China has spent many hundreds of billions of dollars to catch up in semiconductor manufacturing, and has made progress but is still behind. One way of thinking about this is that building hardware requires getting many millions to billions of ideas just right, whereas once you have the hardware, the actual process of training a particular AI system involves dozens to thousands of ideas.
The higher “viscosity” of hardware, compared to ideas about AI algorithms, plus the liquid-like nature of AI capabilities, means that having a single copy of a model doesn’t mean that you can run it at the same scale as the organization you got it from. Stealing o1’s model weights would help you make a rogue o1 API, but it would not be sufficient.

One of the facilities being built as part of OpenAI’s Stargate initiative. A lot of hardware goes towards training, but a lot of hardware is also needed to run AI systems at scale. Even the biggest companies struggle to meet demand. Photo taken from here.
There are a few policy implications of this part of the analogy:
We should plan for the rapid diffusion of AI. We currently rely heavily on the safeguards applied by a small number of frontier AI companies in order to keep society safe (e.g., enabling easier creation of biological weapons). That’s not a sustainable strategy, because those capabilities will spread to other actors, and the more actors with a given level of capability, the more varied their goals and values will be, and some will be very malicious and reckless. The current situation is like having a bunch of delicate electronics and paperwork right next to a big water tank that’s about to burst. We should start much more aggressively AI-proofing many parts of society.
In parallel with planning for some inevitable leaks and spreading of puddles, we also should at least make sure we know how to contain AI systems when we really need to. We should do a much better job of protecting some AI systems from theft, tampering, and misuse – see here and here (and the links therein) for further discussion. Developing frontier AI in the companies that are currently doing so is like storing acid in a bathtub – the acid will eat right through the bathtub, and needs special containers, instead.
Conclusion
There is no perfect analogy for AI.
In order to understand AI, the most important thing is to use it. See what works and what doesn’t, get a sense for how this varies across different products, how the inputs and settings change the outputs, how the speed and performance of cloud-based AI differs from what you can fit on your computer, how performance is changing over time, etc.
But humans think analogically, and I hope this post helps a bit in improving the clarity of your thinking. I also hope it encourages you to be a bit more skeptical when you hear someone use phrases that suggest AI is something more solid than it really is (e.g., “racing to AGI” or “an AGI monopoly”).
Acknowledgments: Thanks to Larissa Schiavo for helpful feedback.
This is technically true of solids, as well, in that measurement units for them are arbitrary. But some aspects of solids are less arbitrary and more discrete, such as crystallization, and at a microscale (i.e., atoms), things are less arbitrary – e.g., counting up the number of atoms in matter is more principled than cups and quarts.
Or more precisely, “open weight,” which is more common than actual open source, because data and other details are rarely released alongside model weights. Notable exceptions on the pre-training side include OLMo, and there are also various post-training datasets available, where there are fewer sensitivities on copyright.